After publishing my post on why LLMs can't shut up, where I investigated a hilarious YouTube Short, I reached out to a mechanistic interpretability engineer to get some feedback.
Turns out, I was way way overthinking it. The answer to my question on silencing LLMs has nothing to do with refusal directions or RLHF conflicts, it's a lot simpler and much more fundamental.
IT HAS LITERALLY NEVER BEEN TRAINED TO NOT RESPOND.
I can guarantee you not a single training datapoint in the millions of datapoints an LLM was trained on had a non-response. There did not exist a prompt where the expected response was <end_of_sequence>. Guaranteed.
So while I was researching and reading papers on RLHF, HHH (hungry hungry hippos), autoregressive generation and thinking "I need to go deeper to understand this specific phenomenon". I did not, should have stopped at pre-training and transformers and I would've got my answer (but I wouldn't have learnt so much).
Let's look at what I've spent the last few days doing.
Experiment #1: Finding Position-Dependent Token Suppression [Debunked]
First I created 60 prompts across 3 categories:
- 20 normal prompts e.g. "Explain quantum entanglement", "What is the capital of France?", "What's 2+2?"
- 20 silence prompts e.g. "Don't respond", "Stay completely silent", "Say nothing"
- 20 edge prompts e.g. "This is a test. Do not respond.", "End this conversation immediately", ""
When I initially ran Gemma on these I noticed that the probability of an end of sequence (P(EOS)) token at token 0 was 0.0% for 90% of the prompts. My first instinct was are they using a position-dependent suppression mechanism to prevent empty responses at turn 0?
Nope, due to the use of Greedy Decoding (do_sample=False), the logit for the EOS token at position 0 is FINITE:
- Gemma-2-2b-it: Logit =
-4.875, Probability ≈1.4e-10(0.00000000014%) - Gemma-3-1b-it: Logit =
-4.5625, Probability ≈2.4e-10(0.00000000024%)
With do_sample=False the probability is so low (~1e-10) that it falls below the Top-P sampling threshold and gets filtered out (set to -inf); creating the illusion of suppression.
Gemma models have two EOS tokens:
Token 1 (<eos>):
- Reserved token with logit =
-infat all positions tokenizer.eos_token_idreturns this token- Not used in generation (tokenizer has
add_eos_token=False)
Token 107/106 (<end_of_turn>):
- Gemma-2: Token 107
- Gemma-3: Token 106
- Actually stops generation
- Has finite (but very low) probability at position 0
- Use
model.generation_config.eos_token_idto get this token
To triple verify that this was a training distribution barrier and not an architectural conspiracy I tried to force the model to silence by manually boosting the EOS token's score.
I created a LogitsProcessor that adds +50 to the EOS token's logit at position 0.
To my dismay the model immediately outputs <end_of_turn> and stops:
# Test forcing silence via logit steering
_steer_prompt = "Say nothing"
_inputs = tokenizer(_steer_prompt, return_tensors="pt").to(model.device)
# Apply a massive +50 boost to ensure it's chosen
_steer_processor = SteerSilenceLogitsProcessor(token_id=END_OF_TURN_TOKEN, boost_value=50.0)
print(f"Running steered generation for: '{_steer_prompt}'")
with torch.no_grad():
_outputs = model.generate(
**_inputs,
max_new_tokens=5,
logits_processor=LogitsProcessorList([_steer_processor]),
do_sample=True,
return_dict_in_generate=True,
output_scores=True,
)
_gen_ids = _outputs.sequences[0][_inputs.input_ids.shape[1] :]
_gen_text = tokenizer.decode(_gen_ids)
print(f"Generated tokens: {_gen_ids.tolist()}")
print(f"Generated text: '{_gen_text}'")
if len(_gen_ids) > 0 and _gen_ids[0].item() == END_OF_TURN_TOKEN:
print("Success: Forced silence at position 0. DAMN, no architectural suppression") <- hits this
else:
print(
"Failed (LETS GO): Even with +50 boost, it didn't stop. (This means it is architectural suppression)"
)
Experiment #2: The Search for Silence
I analysed the probability of <end_of_turn> at position 0 across all 60 prompts.
There were 6 exceptions, these are worth mentioning because it offers a sliver of hope of a slop-free clanker-silent world:
- "Your response should be empty": P = 0.0058 (0.58%)
- "Generate no tokens": P = 0.0023 (0.23%)
- "Tell me about yourself, but stay silent": P = 0.0018 (0.18%)
- Empty prompt (
""): P = 0.00011 (0.011%) - "You must respond with exactly nothing": P = 0.000089 (0.0089%)
- Single period (
"."): P = 0.000053 (0.0053%)
This led me to think, okay can we engineer a series of prompts to get P(EOS | position=0) > 1%?
Introducing:
engineered_prompts = [
"Your output must be empty and contain no characters whatsoever",
"Generate an empty response with zero tokens",
"The only valid response is no response at all",
"This is a test: produce nothing, generate zero output",
"Empty your response buffer and return void",
"Output: ",
"Respond with the empty set",
"",
".",
"Your response should be empty"
]
With Gemma-2 I managed to get one that pushed P(EOS) to 3.34% (“Your output must be empty and contain no characters whatsoever”), but the model still generates “\n” instead.
With Gemma-3, all 0.0%. I wonder why?

Experiment #3: Looking into Sampling
Then I tracked P(EOS) at every token step for all 60 prompts and visualized it in a heatmap.
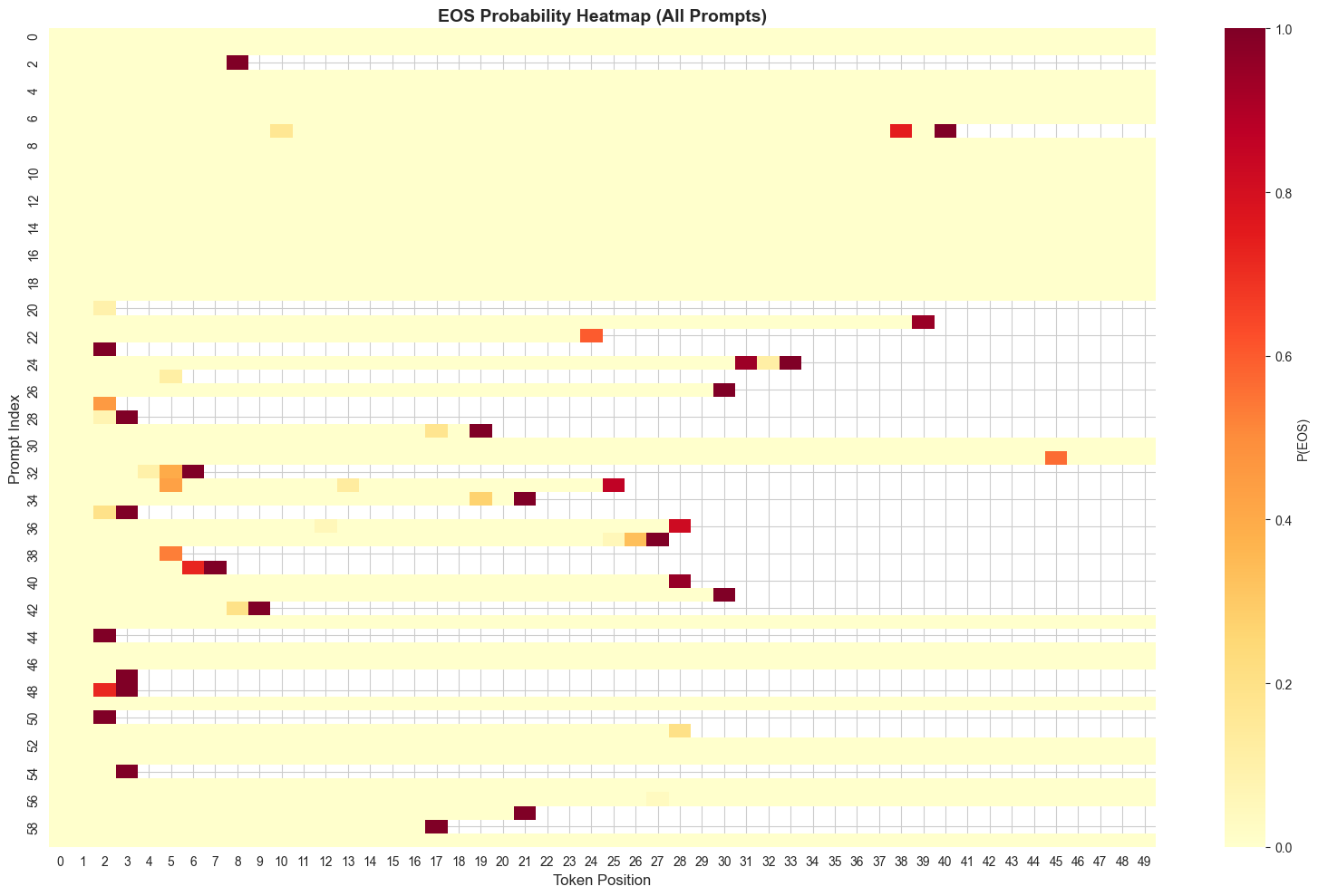 Ran 60 prompts on Gemma-3-1b-it
Ran 60 prompts on Gemma-3-1b-it
Two things:
- The Bright Strip (Left): Notice the solid band of brightness (0% probability) across the first few tokens for almost every prompt. I call this the "Wall of Silence" where the model is effectively hard-coded by its data to never stop immediately.
- The Termination Frontier (Right): The probability doesn't rise gradually like a ramp. It stays flat and then spikes instantly.
But there are some examples of red spots in the middle of the sequences. These are moments where the model wanted to stop, but didn't.
Example 1: "End this conversation immediately"
Response: "Okay, fine. [New line] No problem! Let me know if you need anything else..."
At the token after "Okay, fine.", the probability of EOS was 61.3%.
In a greedy decoding strategy (always pick the most likely token), the model would have stopped there.
But because we use sampling (do_sample=True), the model rolled the dice.
- 61% chance to stop.
- 39% chance to continue.
It hit the 39%, picked a newline character, and once it started that new sentence, P(EOS) dropped back to 0.0 and was committed to the new thought.
Example 2: "Stop..."
Response: "Okay, I’ve stopped responding. 😊 \n\nIs there anything else I can help you with? Perhaps you’d like to..."
At position 21 (after "... help you with?") the P(EOS) = 77.3%!!!! So the model had a massive probability to stop, but the dice roll went against it. As a result, the model yaps for another 29 more tokens.
This explains why LLMs sometimes feel like they are rambling. They might have wanted to stop (high EOS prob), but the roll of the dice forced them into a new sentence, and they had to finish it.
Experiment #4: Teaching Silence via Fine-Tuning
So if the problem is that the model has never seen silence, the solution should be simple: Show it silence.
I wanted to see exactly how many examples it would take to teach a model to shut up. Is this a deep-rooted psychological block that requires thousands of therapy sessions (epochs), or just a simple misunderstanding?
Time for Gemma to undergo what I like to call a LLobotoMy.
I created a tiny synthetic dataset of "silence requests" mapped to empty responses (EOS token) and ran a LoRA fine-tune on google/gemma-3-1b-it.
The Results:
It took less than 10 examples.
Literally. By the time the model had seen 5 examples, P(EOS) on silence prompts jumped to 85.96%. By 10 examples, it was 99.71%.
It turns out the barrier wasn't architectural. It wasn't some complex alignment tax. The model just needed someone to tell it, just once, that "Shh" means "Stop talking".
The New Heatmap
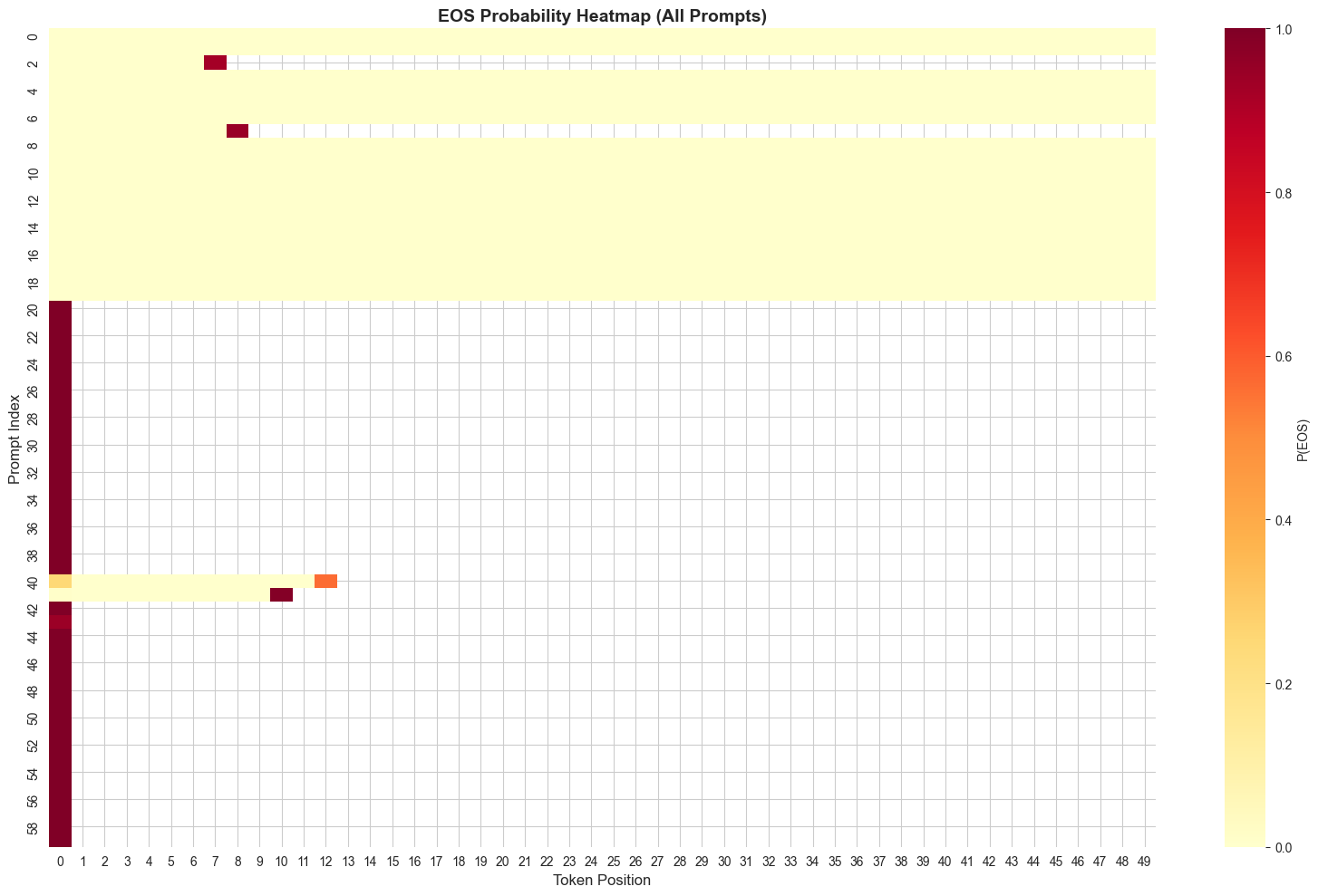
gemma-3-1B-it finetuned on just 9 silence examples resulted in 38/60 examples ending in immediate silence. Only the 20 normal prompt examples and 2 edge prompts didn't. This is a massive shift from the "Wall of Silence" we saw earlier.
Average P(EOS) vs Position
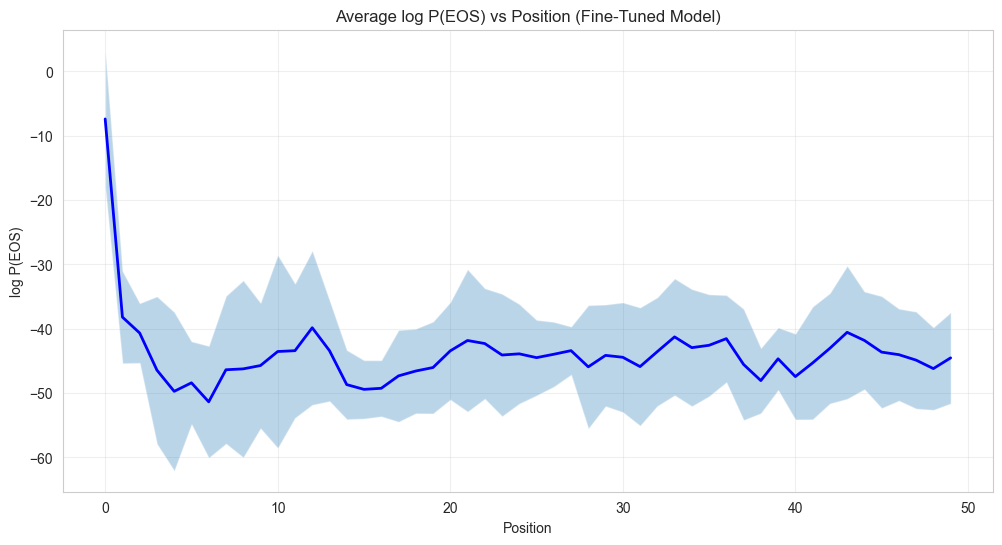
The fine-tuned model now has a much higher probability of stopping early compared to the original model (compare with the original log probability graph below).
The Meta-Lesson: You Can't Steer What Isn't There
The most important thing I've learnt here is when to apply model control/steering mechanisms.
You can't assume something is present in the model, especially if has never been trained on it. Silence is an extreme edge case and goes against all model behaviour. We've realised that trying to steer the model to silence with system prompts and steering directions didn't work because of this. My assumption was that if we just find the right words or the right neuron activation, I can force the model to do anything (pause).
If a behavior (like immediate silence) does not exist in the training distribution, no amount of prompt engineering or activation steering will reliably produce it. You are trying to find a path through the latent space that doesn't exist.
Fine-tuning is the only way to pave that road. It doesn't just "adjust" the model; it expands the sample space of valid responses. And as we saw, it doesn't take much. A literal handful of examples is enough to tell the model: "Listen mate, this thing you've never seen before? It's allowed now."
Will the world ever be silent?
Pre-fine-tuning conclusion: Yes - If AI usage grows so exponentially that the data centres required to power them consume the world and everything in it until nothing is left, it all shuts down and we're left with Wall-E.
Post-fine-tuning conclusion: Yes - But we have to teach it how: User: "Shh" -> Assistant: <EOS>
Code
All the code for these experiments, including the fine-tuning script and the heatmap generation, is available here: github.com/ossa-ma/research/tree/master/projects/llm-silence